
My proposal
受到王维论文的启发,基于他的思路,我提出了在1ms系统上实现物体位姿预测的proposal,核心有两点:
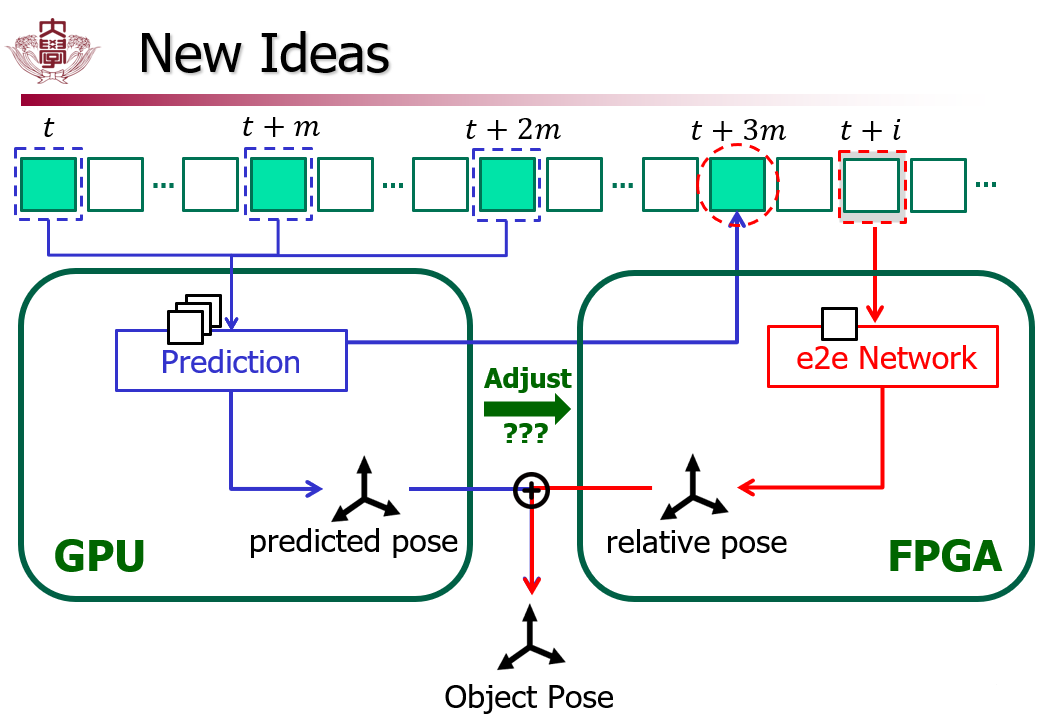
- GPU上实现关键帧Pose Prediction:取连续几帧关键帧,获取他们的temporal和spatial信息来对未来的关键帧进行预测,得到预测的absolute pose。
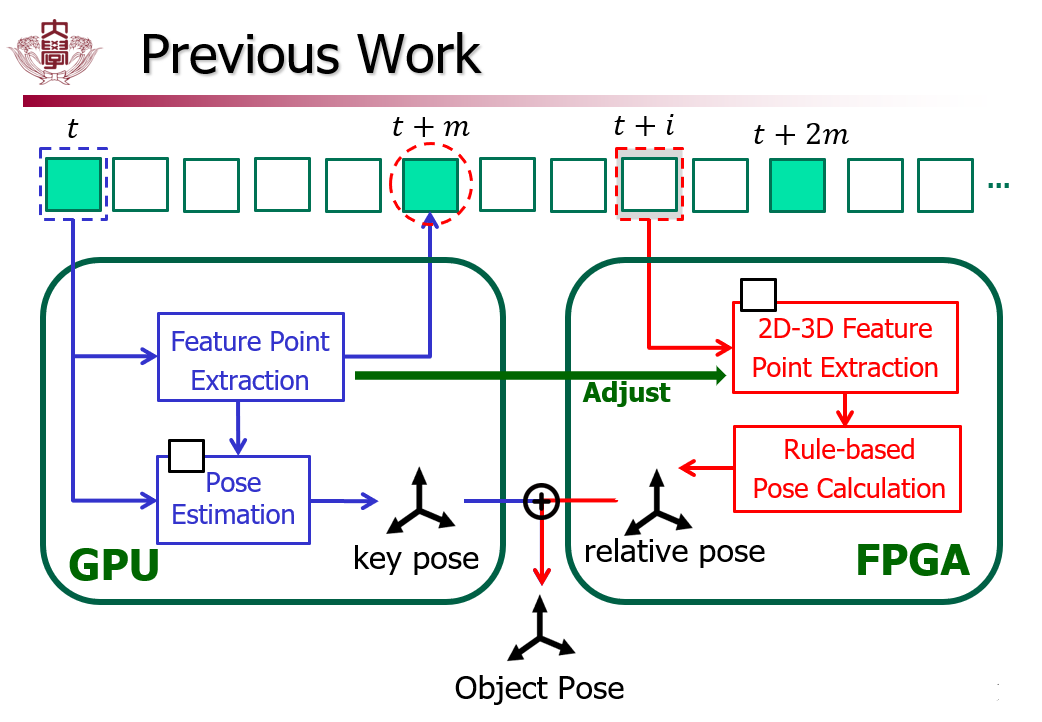
以往的1ms系统的GPU-FPGA结构中,以王维的工作为例,GPU只对当前的一个关键帧进行estimation,在下一个关键帧到来时运算完毕,这中间存在时间差(具体细节会在下一节讲)。如果使用多关键帧进行预测,就能消除这种误差。
- FPGA上部署e2e网络回归一般帧relative pose:使用e2e神经网络,直接回归任意普通帧的relative pose参数。
与王维的工作不同的是,王维通过ORB、2D-3D点匹配、particle filter等算法,对特征点进行提取后分析,然后才得到pose。这显然是rule-based的,鲁棒性有待验证。现在,我要改进为net-based,即直接使用一个端到端的神经网络替代所有rule-based算法。
最后,对于任意一帧:结合GPU上得到的absolute pose(predicted)和FPGA上得到的relative pose,即可得到任意时刻真正的object pose。
这里给出我的idea(右)和previous work(左)的架构对比图:
王维工作:FPGA-GPU架构的细节
由于我后期的研究需要基于王维的这篇论文中的思想,因此需要细致深入的理解。
关键词
| GPU侧 | Key Frame | Key Feature Points | Key Pose (Absolute Pose) |
| FPGA侧 | Normal Frame | Normal Feature Points | Normal Pose (Relative Pose) |
时序
由于这是一个GPU与FPGA协助的结构,因此首先要理解时序问题。关键帧KeyFrame每隔m帧选取一帧,在两个关键帧之间的时间内(即下一个关键帧来到之前),需要GPU完成他对当前关键帧的处理任务;另外,两个关键帧之间的普通帧NormalFrame,参照的是上一个关键帧的estimation结果。具体可以看我画的这张图:

GPU侧
GPU一方面要通过YOLO生成pose,另一方面还需要得到2D-3D特征点和2D-3D映射关系。
过程1将KeyFrame投入YOLO-6D网络,得到pose参数。这个key pose在最后要和一般帧的relative pose结合成真正的output pose,但在GPU上他还需要作为过程2;

过程2的输入是生成的key pose与CAD模型数据,通过Cross-Spatial Fusion模块得到一个遮罩mask与特征点。右侧,key pose用于旋转CAD模型直至与当前pose吻合,用于后续2D-3D特征点映射的生成;左侧,遮罩Mask的作用在论文Fig.3和Fig.4有详细阐述,其作用是辅助生成稳定可靠的特征点,避免了物体在旋转时部分特征点的失效。

FPGA侧
过程3运用传统ORB算法,从一般帧中提取特征点normal feature points。在这个过程中,也借助了GPU侧运算出的关键帧特征点key feature points。

过程4通过粒子滤波的rule-based算法,将特征点信息最终转化为object pose。虽然他的鲁棒性有待考证,但考虑到FPGA的部署问题和1ms的延时需求,王维并没有使用常规的PnP等会给FPGA带来巨大压力的递归算法,这也算是一个好的点。但我做的e2e网络肯定要在这方面打败他 同时我们也要注意到,t+i-1时刻(前一帧)的pose信息被反馈到粒子滤波算法中,用于生成t+i时刻(当前帧)的pose;由此可见,粒子滤波将相邻帧强关联起来。

GPU-FPGA交互
GPU-FPGA交互体现在两个点:
- 协同工作:GPU关键帧Adjust —> FPGA每个一般帧。
- 最后阶段:GPU与FPGA得到的key-pose与relative-pose整合为最终输出pose。
从图里也可以很清晰地看到,GPU侧得到的2D和3D特征点传到FPGA中,分别辅助于FPGA上的ORB算法和粒子滤波,进行一般帧特征点提取和特征点推导pose。这一步或许就是传统1ms结构中提到的用当前关键帧Adjust未来帧。


最后一步,关键帧KeyPose和普通帧RelativePose整合成最终输出pose。


